Table of Contents
Chapter 3 introduced numerous concepts and the analysis and design needed to create an implementation of SymmetricDS. This chapter re-visits each analysis step and documents how to turn a SymmetricDS design into reality through configuration of the various SymmetricDS tables. In addition, several advanced configuration options, not presented previously, will also be covered.
To get a SymmetricDS node running, it needs to be given an identity and it needs to know how
to connect to the database it will be synchronizing. A typical way to specify this is to place properties
in the symmetric.properties file. When started up, SymmetricDS reads the configuration
and state from the database. If the configuration tables are missing, they are created
automatically (auto creation can be disabled). Basic configuration is described by inserting into the following tables (the complete
data model is defined in Appendix A, Data Model).
NODE_GROUP - specifies the tiers that exist in a SymmetricDS network
NODE_GROUP_LINK - links two node groups together for synchronization
CHANNEL - grouping and priority of synchronizations
TRIGGER - specifies tables, channels, and conditions for which changes in the database should be captured
ROUTER - specifies the routers defined for synchronization, along with other routing details
TRIGGER_ROUTER - provides mappings of routers and triggers
During start up, triggers are verified against the database, and database triggers are installed on tables that require data changes to be captured. The Route, Pull and Push Jobs begin running to synchronize changes with other nodes.
Each node requires properties that allow it to connect to a database and register with a parent node. To give a node its identity, the following properties are used:
The node group that this node is a member of. Synchronization is specified between node groups, which means you only need to specify it once for multiple nodes in the same group.
The external id for this node has meaning to the user and provides integration into the system where it is deployed. For example, it might be a retail store number or a region number. The external id can be used in expressions for conditional and subset data synchronization. Behind the scenes, each node has a unique sequence number for tracking synchronization events. That makes it possible to assign the same external id to multiple nodes, if desired.
The URL where this node can be contacted for synchronization. At startup and during each heartbeat, the node updates its entry in the database with this URL.
When a new node is first started, it is has no information about synchronizing. It contacts the registration server in order to join the network and receive its configuration. The configuration for all nodes is stored on the registration server, and the URL must be specified in the following property:
The URL where this node can connect for registration to receive its configuration. The registration server is part of SymmetricDS and is enabled as part of the deployment.
When deploying to an application server, it is common for database connection pools to be found in the Java naming directory (JNDI). In this case, set the following property:
The name of the database connection pool to use, which is registered in the JNDI directory tree of the application server. It is recommended that this DataSource is NOT transactional, because SymmetricDS will handle its own transactions.
For a deployment where the database connection pool should be created using a JDBC driver, set the following properties:
The class name of the JDBC driver.
The JDBC URL used to connect to the database.
The database username, which is used to login, create, and update SymmetricDS tables.
The password for the database user.
A node, a single instance of SymmetricDS, is defined in the NODE table. Two other tables play a direct role in defining a node, as well The first is NODE_IDENTITY. The only row in this table is inserted in the database when the node first registers with a parent node. In the case of a root node, the row is entered by the user. The row is used by a node instance to determine its node identity.
The following SQL statements set up a top-level registration server as a node identified as "00000" in the "corp" node group.
insert into SYM_NODE
(node_id, node_group_id, external_id, sync_enabled)
values
('00000', 'corp', '00000', 1);
insert into SYM_NODE_IDENTITY values ('00000');
The second table, NODE_SECURITY has rows created for each child node that registers with the node, assuming auto-registration is enabled. If auto registration is not enabled, you must create a row in NODE and NODE_SECURITY for the node to be able to register. You can also, with this table, manually cause a node to re-register or do a re-initial load by setting the corresponding columns in the table itself. Registration is discussed in more detail in Section 4.7, “Opening Registration”.
Node Groups are straightforward to configure and are defined in the NODE_GROUP table. The following SQL statements would create node groups for "corp" and "store" based on our retail store example.
insert into SYM_NODE_GROUP
(node_group_id, description)
values
('store', 'A retail store node');
insert into SYM_NODE_GROUP
(node_group_id, description)
values
('corp', 'A corporate node');
Similarly, Node Group links are established using a data event action of 'P' for Push and 'W' for Pull ("wait"). The following SQL statements links the "corp" and "store" node groups for synchronization. It configures the "store" nodes to push their data changes to the "corp" nodes, and the "corp" nodes to send changes to "store" nodes by waiting for a pull.
insert into SYM_NODE_GROUP_LINK
(source_node_group, target_node_group, data_event_action)
values
('store', 'corp', 'P');
insert into SYM_NODE_GROUP_LINK
(source_node_group, target_node_group, data_event_action)
values
('corp', 'store', 'W');
By categorizing data into channels and assigning them to TRIGGERs, the user gains more control and visibility into the flow of data. In addition, SymmetricDS allows for synchronization to be enabled, suspended, or scheduled by channels as well. The frequency of synchronization and order that data gets synchronized is also controlled at the channel level.
The following SQL statements setup channels for a retail store. An "item" channel includes data for items and their prices, while a "sale_transaction" channel includes data for ringing sales at a register.
insert into SYM_CHANNEL
(channel_id, processing_order, max_batch_size, max_batch_to_send,
extract_period_millis, batch_algorithm, enabled, description)
values
('item', 10, 1000, 10, 0, 'default', 1, 'Item and pricing data');
insert into SYM_CHANNEL
(channel_id, processing_order, max_batch_size, max_batch_to_send,
extract_period_millis, batch_algorithm, enabled, description)
values
('sale_transaction', 1, 1000, 10, 60000, 'transactional', 1,
'retail sale transactions from register');
Batching is the grouping of data, by channel, to be transferred and committed at the client together. There are three different out-of-the-box batching algorithms which may be configured in the batch_algorithm column on channel.
All changes that happen in a transaction are guaranteed to be batched together. Multiple transactions will be batched and committed together until there is no more data to be sent or the max_batch_size is reached.
Batches will map directly to database transactions. If there are many small database transactions, then there will be many batches. The max_batch_size column has no effect.
Multiple transactions will be batched and committed together until there is no more data to be sent or the max_batch_size is reached. The batch will be cut off at the max_batch_size regardless of whether it is in the middle of a transaction.
SymmetricDS captures synchronization data using database triggers. SymmetricDS' Triggers are defined in the
TRIGGER table.
Each record is used by SymmetricDS when generating database triggers. Database triggers are only generated when a trigger
is associated with a ROUTER whose source_node_group_id matches the node group id of the current node.
The following SQL statement defines a trigger that will capture data for a table named "item" whenever data is inserted, updated, or deleted. The trigger is assigned to a channel also called 'item'.
insert into SYM_TRIGGER
(trigger_id,source_table_name,channel_id,last_update_time,create_time)
values
('item', 'item', 'item', current_timestamp, current_timestamp);
Routers provided in the base implementation currently include:
The mapping between the set of triggers and set of routers is many-to-many. This means that one trigger can capture changes and route to multiple locations. It also means that one router can be defined an associated with many different triggers.
The simplest router is a router that sends all the data that is captured by its associated triggers to all the nodes that belong to the target node group defined in the router. A router is defined as a row in the ROUTER table. It is then linked to triggers in the TRIGGER_ROUTER table.
The following SQL statement defines a router that will send data from the 'corp' group to the 'store' group.
insert into SYM_ROUTER
(router_id, source_node_group_id, target_node_group_id,
create_time, last_update_time)
values
('corp-2-store','corp', 'store', current_timestamp, current_timestamp);
The following SQL statement maps the 'corp-2-store' router to the item trigger.
insert into SYM_TRIGGER_ROUTER
(trigger_id, router_id, initial_load_order, create_time, last_update_time)
values
('item', 'corp-2-store', 1, current_timestamp, current_timestamp);
Sometimes requirements may exist that require data to be routed based on the current value or the old value of a
column in the table that is being routed. Column routers are configured by setting the router_type column on the
ROUTER table
to column and setting the router_expression column to an equality expression that represents
the expected value of the column.
The first part of the expression is always the column name. The column name should always be defined in upper case. The upper case column name prefixed by OLD_ can be used for a comparison being done with the old column data value.
The second part of the expression can be a constant value, a token that represents another column, or a token that represents some other SymmetricDS concept. Token values always begin with a colon (:).
Consider a table that needs to be routed to all nodes in the target group only when a status column is set to 'OK.' The following SQL statement will insert a column router to accomplish that.
insert into SYM_ROUTER
(router_id, source_node_group_id, target_node_group_id, router_type,
router_expression, create_time, last_update_time)
values
('corp-2-store-ok','corp', 'store', 'column',
'STATUS=OK', current_timestamp, current_timestamp);
Consider a table that needs to be routed to all nodes in the target group only when a status column changes values. The following SQL statement will insert a column router to accomplish that.
insert into SYM_ROUTER
(router_id, source_node_group_id, target_node_group_id, router_type,
router_expression, create_time, last_update_time)
values
('corp-2-store-status','corp', 'store', 'column',
'STATUS!=:OLD_STATUS', current_timestamp, current_timestamp);
Consider a table that needs to be routed to only nodes in the target group whose STORE_ID column matches the external id of a node. The following SQL statement will insert a column router to accomplish that.
insert into SYM_ROUTER
(router_id, source_node_group_id, target_node_group_id, router_type,
router_expression, create_time, last_update_time)
values
('corp-2-store-id','corp', 'store', 'column',
'STORE_ID=:EXTERNAL_ID', current_timestamp, current_timestamp);
Attributes on a NODE that can be referenced with tokens include:
Consider a table that needs to be routed to a redirect node defined by its external id in the REGISTRATION_REDIRECT table. The following SQL statement will insert a column router to accomplish that.
insert into SYM_ROUTER
(router_id, source_node_group_id, target_node_group_id, router_type,
router_expression, create_time, last_update_time)
values
('corp-2-store-redirect','corp', 'store', 'column',
'STORE_ID=:REDIRECT_NODE', current_timestamp, current_timestamp);
More than one column may be configured in a router_expression. When more than one column is configured, all matches are added to the list of nodes to route to. The following is an example where the STORE_ID column may contain the STORE_ID to route to or the constant of ALL which indicates that all nodes should receive the update.
insert into SYM_ROUTER
(router_id, source_node_group_id, target_node_group_id, router_type,
router_expression, create_time, last_update_time)
values
('corp-2-store-multiple-matches','corp', 'store', 'column',
'STORE_ID=ALL
STORE_ID=:EXTERNAL_ID', current_timestamp, current_timestamp);
The NULL keyword may be used to check if a column is null. If the column is null, then data will be routed to all nodes who qualify for the update. This following is an example where the STORE_ID column is used to route to a set of nodes who have a STORE_ID equal to their EXTERNAL_ID, or to all nodes if the STORE_ID is null.
insert into SYM_ROUTER
(router_id, source_node_group_id, target_node_group_id, router_type,
router_expression, create_time, last_update_time)
values
('corp-2-store-multiple-matches','corp', 'store', 'column',
'STORE_ID=NULL
STORE_ID=:EXTERNAL_ID', current_timestamp, current_timestamp);
A lookup table may contain the id of the node where data needs to be routed. This could be an existing table or an ancillary table that is added
specifically for the purpose of routing data. Lookup table routers are configured by setting the router_type column on the
ROUTER table
to lookuptable and setting a list of configuration parameters in the router_expression column.
Each of the following configuration parameters are required.
This is the name of the lookup table.
This is the name of the column on the table that is being routed. It will be used as a key into the lookup table.
This is the name of the column that is the key on the lookup table.
This is the name of the column that contains the external_id of the node to route to on the lookup table.
Note that the lookup table will be read into memory and cached for the duration of a routing pass for a single channel.
Consider a table that needs to be routed to a specific store, but the data in the changing table only contains brand information. In this case, the STORE table may be used as a lookup table.
insert into SYM_ROUTER
(router_id, source_node_group_id, target_node_group_id, router_type,
router_expression, create_time, last_update_time)
values
('corp-2-store-ok','corp', 'store', 'lookuptable',
'LOOKUP_TABLE=STORE
KEY_COLUMN=BRAND_ID
LOOKUP_KEY_COLUMN=BRAND_ID
EXTERNAL_ID_COLUMN=STORE_ID', current_timestamp, current_timestamp);
Sometimes routing decisions need to be made based on data that is not in the current row being synchronized. Consider an example where an Order table and a OrderLineItem table need to be routed to a specific store. The Order table has a column named order_id and STORE_ID. A store node has an external_id that is equal to the STORE_ID on the Order table. OrderLineItem, however, only has a foreign key to its Order of order_id. To route OrderLineItems to the same nodes that the Order will be routed to, we need to reference the master Order record.
There are two possible ways to route the OrderLineItem in SymmetricDS. One is to configure a 'subselect' router_type on the ROUTER table and the other is to configure an external_select on the TRIGGER table.
A 'subselect' is configured with a router_expression that is a SQL select statement which returns a result set of the node_ids that need routed to. Column tokens can be used in the SQL expression and will be replaced with row column data. The overhead of using this router type is high because the 'subselect' statement runs for each row that is routed. It should not be used for tables that have a lot of rows that are updated. It also has the disadvantage that if the Order master record is deleted, then no results would be returned and routing would not happen. The router_expression is appended to the following SQL statement in order to select the node ids.
select c.node_id from sym_node c where c.node_group_id=:NODE_GROUP_ID and c.sync_enabled=1 and
Consider a table that needs to be routed to all nodes in the target group only when a status column is set to 'OK.' The following SQL statement will insert a column router to accomplish that.
insert into SYM_ROUTER
(router_id, source_node_group_id, target_node_group_id, router_type,
router_expression, create_time, last_update_time)
values
('corp-2-store','corp', 'store', 'subselect',
'c.external_id in (select STORE_ID from order where order_id=:ORDER_ID)',
current_timestamp, current_timestamp);
Alternatively, when using an external_select on the TRIGGER table, data is captured in the EXTERNAL_DATA column of the DATA table at the time a trigger fires. The EXTERNAL_DATA can then be used for routing by using a router_type of 'column'. The advantage of this approach is that it is very unlikely that the master Order table will have been deleted at the time any DML accures on the OrderLineItem table. It also is a bit more effcient than the 'subselect' approach, although the triggers produced do run the extra external_select inline with application database updates.
In the following example, the STORE_ID is captured from the Order table in the EXTERNAL_DATA column. EXTERNAL_DATA is always available for routing as a virtual column in a 'column' router. The router is configured to route based on the captured EXTERNAL_DATA to all nodes whose external_id matches. Note that other supported node attribute token can also be used for routing.
insert into SYM_TRIGGER
(trigger_id,source_table_name,channel_id,external_select,
last_update_time,create_time)
values
('orderlineitem', 'orderlineitem', 'orderlineitem','select STORE_ID
from order where order_id=$(curTriggerValue).$(curColumnPrefix)order_id',
current_timestamp, current_timestamp);
insert into SYM_ROUTER
(router_id, source_node_group_id, target_node_group_id, router_type,
router_expression, create_time, last_update_time)
values
('corp-2-store-ext','corp', 'store', 'column',
'EXTERNAL_DATA=:EXTERNAL_ID', current_timestamp, current_timestamp);
When more flexibility is needed in the logic to choose the nodes to route to, then the a Bean Shell router may be used. Bean Shell is a Java-like scripting language. Documentation for the Bean Shell scripting language can be found at http://www.beanshell.org.
The router_type for a Bean Shell router is 'bsh'. The router_expression is a valid Bean Shell script that:
Also bound to the script evaluation is a list of 'nodes'. The list of 'nodes' is a list of eligible Node objects. The current data column values and the old data column values are bound to the script evaluation as Java object representations of the column data. The columns are bound using the uppercase names of the columns. Old values are bound to uppercase representations that are prefixed with 'OLD_'.
In the following example, the node_id is a combination of STORE_ID and WORKSTATION_NUMBER, both of which are columns on the table that is being routed.
insert into SYM_ROUTER
(router_id, source_node_group_id, target_node_group_id, router_type,
router_expression, create_time, last_update_time)
values
('corp-2-store-bsh','corp', 'store', 'bsh',
'targetNodes.add(STORE_ID + "-" + WORKSTATION_NUMBER);',
current_timestamp, current_timestamp);
The same could also be accomplished by simply returning the node id. The last line of a bsh script is always the return value.
insert into SYM_ROUTER
(router_id, source_node_group_id, target_node_group_id, router_type,
router_expression, create_time, last_update_time)
values
('corp-2-store-bsh','corp', 'store', 'bsh',
'STORE_ID + "-" + WORKSTATION_NUMBER',
current_timestamp, current_timestamp);
The following example will synchronize to all nodes if the FLAG column has changed, otherwise no nodes will be synchronized.
insert into SYM_ROUTER
(router_id, source_node_group_id, target_node_group_id, router_type,
router_expression, create_time, last_update_time)
values
('corp-2-store-flag-changed','corp', 'store', 'bsh',
'FLAG != null && !FLAG.equals(OLD_FLAG)',
current_timestamp, current_timestamp);
Node registration is the act of setting up a new NODE and
NODE_SECURITY so that when the new node is brought online
it is allowed to join the system. Nodes are only allowed to register if rows exist for the
node and the registration_enabled flag is set to 1. If the auto.registration
SymmetricDS property is set to true, then when a node attempts to register, if registration
has not already occurred, the node will automatically be registered.
SymmetricDS allows you to have multiple nodes with the same external_id. Out of the box, openRegistration
will open a new registration if a registration already exists for a node with the same external_id. A new
registration means a new node with a new node_id and the same external_id will be created.
If you want to re-register the same node you can use the reOpenRegistration() JMX
method which takes a node_id as an argument.
An initial load is the process of seeding tables at a target node with data from its parent node.
An initial load can not occur until after a node is registered. An initial load is
requested by setting the initial_load_enabled column on NODE_SECURITY to
1 on the row for the target node in the parent node's database. The next time the
target node synchronizes, reload batches will be inserted. At the same time reload batches
are inserted, all previously pending batches for the node are marked as successfully sent.
SymmetricDS recognizes that an initial load has completed when the initial_load_time column on the
target node is set to a non null value.
Reload batches are inserted in order according to the initial_load_order column on
TRIGGER_ROUTER. Initial load data is always queried from the
source database table. All data is passed through the configured router to filter out data that
might not be targeted at a node.
A more efficient way to subset the data for a load is to provide an
initial_load_select clause on TRIGGER_ROUTER.
If an initial_load_select clause is provided, data will not be passed through the
configured router during initial load. In cases where custom routing is done using a feature like Section 4.6.2.4, “Relational Router”,
an initial_load_select clause will always need to be provided because the router would not
function properly with initial load data.
When providing an initial_load_select be sure to test out the criteria against production data in a query browser. Do an explain plan to make sure you are properly using indexes.
Occasionally the decision of what data to load initially results in additional triggers. These triggers, known as Dead Triggers,
are configured such that they do not capture any data changes.
A "dead" Trigger is one that does not capture data changes.
In other words, the sync_on_insert, sync_on_update, and sync_on_delete properties
for the Trigger are all set to false. However, since the Trigger is specified, it will
be included in the initial load of data for target Nodes.
Why might you need a Dead Trigger? A dead Trigger might be used to load a read-only lookup table, for example. It could also be used to load a table that needs populated with example or default data. Another use is a recovery load of data for tables that have a single direction of synchronization. For example, a retail store records sales transaction that synchronize in one direction by trickling back to the central office. If the retail store needs to recover all the sales transactions from the central office, they can be sent are part of an initial load from the central office by setting up dead Triggers that "sync" in that direction.
The following SQL statement sets up a non-syncing dead Trigger that sends
the sale_transaction table to the "store" Node Group from the "corp" Node Group during
an initial load.
insert into sym_trigger (TRIGGER_ID,SOURCE_CATALOG_NAME,
SOURCE_SCHEMA_NAME,SOURCE_TABLE_NAME,CHANNEL_ID,
SYNC_ON_UPDATE,SYNC_ON_INSERT,SYNC_ON_DELETE,
SYNC_ON_INCOMING_BATCH,NAME_FOR_UPDATE_TRIGGER,
NAME_FOR_INSERT_TRIGGER,NAME_FOR_DELETE_TRIGGER,
SYNC_ON_UPDATE_CONDITION,SYNC_ON_INSERT_CONDITION,
SYNC_ON_DELETE_CONDITION,EXTERNAL_SELECT,
TX_ID_EXPRESSION,EXCLUDED_COLUMN_NAMES,
CREATE_TIME,LAST_UPDATE_BY,LAST_UPDATE_TIME)
values ('SALE_TRANSACTION_DEAD',null,null,
'SALE_TRANSACTION','transaction',
0,0,0,0,null,null,null,null,null,null,null,null,null,
current_timestamp,'demo',current_timestamp);
insert into sym_router (ROUTER_ID,TARGET_CATALOG_NAME,TARGET_SCHEMA_NAME,
TARGET_TABLE_NAME,SOURCE_NODE_GROUP_ID,TARGET_NODE_GROUP_ID,ROUTER_TYPE,
ROUTER_EXPRESSION,SYNC_ON_UPDATE,SYNC_ON_INSERT,SYNC_ON_DELETE,
CREATE_TIME,LAST_UPDATE_BY,LAST_UPDATE_TIME)
values ('CORP_2_STORE',null,null,null,
'corp','store',null,null,1,1,1,
current_timestamp,'demo',current_timestamp);
insert into sym_trigger_router (TRIGGER_ID,ROUTER_ID,INITIAL_LOAD_ORDER,
INITIAL_LOAD_SELECT,CREATE_TIME,LAST_UPDATE_BY,LAST_UPDATE_TIME)
values ('SALE_TRANSACTION_DEAD','CORP_2_REGION',100,null,
current_timestamp,'demo',current_timestamp);
SymmetricDS allows tables to be synchronized bi-directionally. Note that an outgoing
synchronization does not process changes during an incoming synchronization on the same node unless the trigger
was created with the sync_on_incoming_batch flag set. If the sync_on_incoming_batch flag
is set, then update loops are prevented by a feature that is available in most database dialects.
More specifically, during an incoming synchronization the source node_id is put into a database session variable that is
available to the database trigger. Data events are not generated if the target node_id
on an outgoing synchronization is equal to the source node_id.
By default, only the columns that changed will be updated in the target system.
More complex conflict resolution strategies can be accomplished by using the
IDataLoaderFilter extension point which has access to both
old and new data.
As shown in Section 3.2, “Organizing Nodes”, there may be scenarios where data needs to flow through multiple tiers of nodes that are organized in a tree-like network with each tier requiring a different subset of data. For example, you may have a system where the lowest tier may by a computer or device located in a store. Those devices may connect to a server located physically at that store. Then the store server may communicate with a corporate server for example. In this case, the three tiers would be device, store, and corporate. Each tier is typically represented by a node group. Each node in the tier would belong to the node group representing that tier.
A node will always push and pull data to other node groups according to the node group link configuration.
A node can only pull and push data to other nodes that are represented node table in its database and
having sync_enabled = 1.
Because of this, a tree-like
hierarchy of nodes can be created by having only a subset of nodes belonging to the same node group represented at the different branches of the tree.
If auto registration is turned off, then this setup must occur manually by opening registration
for the desired nodes at the desired parent node and by configuring each node's registration.url
to be the parent node's URL.
The parent node is always tracked by the setting of the parent's node_id in the created_at_node_id column of the new node.
When a node registers and downloads its configuration it is always provided the configuration for nodes
that might register with the node itself based on the Node Group Links defined in the parent node.
When deploying a multi-tiered system it may be advantageous to have only one registration server, even though the parent node of a registering node
could be any of a number of nodes in the system. In SymmetricDS the parent node is always the node that a child registers with. The
REGISTRATION_REDIRECT table allows a single node, usually the root server in the network, to
redirect registering nodes to their true parents. It does so based on a mapping found in the table of the external id (registrant_external_id) to the parent's node
id (registration_node_id).
For example, if it is desired to have a series of regional servers that workstations at retail stores get assigned to based on their external_id, the store number, then
you might insert into REGISTRATION_REDIRECT the store number as the registrant_external_id and the node_id of
the assigned region as the registration_node_id. When a workstation at the store registers, the root server send an HTTP redirect to the sync_url of the node
that matches the registration_node_id.
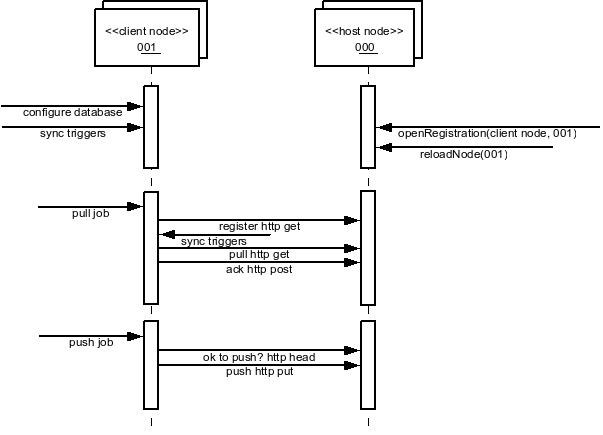
The SymmetricDS software allows for outgoing and incoming changes to be synchronized to/from other databases. The node that initiates a synchronization connection is the client, and the node receiving a connection is the host. Because synchronization is configurable to push or pull in either direction, the same node can act as either a client or a host in different circumstances.
The SymmetricDS software consists of a series of background jobs, managers, Servlets, and services wired together via dependency injection using the Spring Framework.
As a client, the node runs the router job, push job and pull job on a timer thread. The router job uses services to create batches that are targeted at certain nodes. The push job uses services to extract and stream data to another node (that is, it pushes data). The response from a push is a list of batch acknowlegements to indicate that data was loaded. The pull job uses services to load data that is streamed from another node (i.e., it pulls data). After loading data, a second connection is made to send a list of batch acknowlegements.
As a host, the node waits for incoming connections that pull, push, or acknowledge data changes. The push Servlet uses services to load data that is pushed from a client node. After loading data, it responds with a list of batch acknowledgements. The pull Servlet uses services to extract, and stream data back to the client node. The ack Servlet uses services to update the status of data that was loaded at a client node. The router job batches and routes data.
By default, data is extracted from the source database into memory until a threshold size is reached. If the threshold size is reached, data is streamed to a temporary file in the JVM's default temporary directory. Next, the data is streamed to the target node across the transport layer. The receiving node will cache the data in memory until the threshold size is reached, writing to a temporary file if necessary. At last, the data is loaded into the target database by the data loader. This step by step approach allows for extract time, transport time, and load time to all be measured independently. It also allows database resources to be used most optimally.
The transport manager handles the incoming and outgoing streams of data between nodes. The default transport is based on a simple implementation over HTTP. An internal transport is also provided. It is possible to add other implementations, such as a socket-based transport manager.
Node communication over HTTP is represented in the following figure.
The StandaloneSymmetricEngine is wrapper API that can be used to directly start the client services only. The
SymmetricWebServer is a wrapper API that can be used to directly start both the
client and host services inside a Jetty web container. The SymmetricLauncher provides command line tools to work
with and start SymmetricDS.
The frequency of data synchronization is controlled by the coordination of a series of asynchronous events.
After data is captured, the first event that occurs is the routing of the
captured DATA rows. Data is routed by the Route Job. It is a single background task that inserts into
DATA_EVENT and OUTGOING_BATCH. The Route Job determines which nodes
data will be sent to, as well as how much data will be batched together for transport. When the start.route.job SymmetricDS property is set to
true, the frequency that routing occurs is controlled by the job.routing.period.time.ms. Each time data is routed, the
DATA_REF table is updated with the id of the last contiguous data row to have been processed. This is done so the query to find
unrouted data is optimal.
After data is routed, it awaits transport to the target nodes. Transport can occur when a client node is configured to pull data or when the host node is configured to push data. These
events are controlled by the Push and the Pull Jobs. When the start.pull.job SymmetricDS property is set to
true, the frequency that data is pulled is controlled by the job.pull.period.time.ms. When the start.push.job SymmetricDS property is set to
true, the frequency that data is pushed is controlled by the job.push.period.time.ms. Data is extracted by channel from the source database's
DATA table at an interval controlled by the extract_period_millis column on the
CHANNEL table. The last_extract_time is
always recorded, by channel, on the NODE_CHANNEL_CTL table for the host node's id. When the Pull and Push Job run, if the extract period
has not passed according to the last extract time, then the channel will be skipped for this run. If the extract_period_millis is set to zero, data extraction will happen every time the jobs run.
SymmetricDS also provides the ability to configure windows of time when synchronization is allowed. This is done using the
NODE_GROUP_CHANNEL_WINDOW
table. A list of allowed time windows can be specified for a node group and a channel. If one or more windows exist, then data will only be extracted and transported if the time
of day falls within the window of time specified. The configured times are always for the target node's local time. If the start_time is greater than the end_time, then the window crosses
over to the next day.
All data loading may be disabled by setting the dataloader.enable property to false. This has the effect of not allowing incoming synchronizations, while allowing outgoing
synchronizations. All data extractions may be disabled by setting the dataextractor.enable property to false. These properties can be controlled by inserting into the
root server's PARAMETER table. These properties affect every channel with the exception of the 'config' channel.
SymmetricDS examines the current configuration, corresponding database triggers, and the underlying tables to determine if database triggers need created or updated. The change activity is recorded on the TRIGGER_HIST table with a reason for the change. The following reasons for a change are possible:
N - New trigger that has not been created before
S - Schema changes in the table were detected
C - Configuration changes in Trigger
T - Trigger was missing
A configuration entry in Trigger without any history in Trigger Hist results in a new
trigger being created (N). The Trigger Hist stores a hash of the underlying table, so
any alteration to the table causes the trigger to be rebuilt (S). When the
last_update_time is changed on the Trigger entry, the configuration change causes
the trigger to be rebuilt (C). If an entry in Trigger Hist is missing the
corresponding database trigger, the trigger is created (T).
The process of examining triggers and rebuilding them is automatically run during startup and
each night by the SyncTriggersJob. The user can also manually run the process at any time
by invoking the syncTriggers() method over JMX. The SyncTriggersJob is enabled by default
to run at 15 minutes past midnight. If SymmetricDS is being run from a collection of servers
(multiple instances of the same Node running against the same database), then locking
should be enable to prevent database contention. The following runtime properties
control the behavior of the process.
Whether the sync triggers job is enabled for this node. [ Default: true ]
If scheduled, the sync triggers job will run nightly. This is how long after midnight that job will run. [ Default: 15 ]
Indicate if the sync triggers job is clustered and requires a lock before running. [ Default: false ]
With the proper configuration SymmetricDS can publish XML messages of captured data changes to JMS during routing or transactionally while data loading synchronized data into a target database. The following explains how to publish to JMS during synchronization to the target database.
The XmlPublisherDataLoaderFilter is a IDataLoaderFilter that may be configured to publish specific tables as an XML message to a JMS provider. See Chapter 6, Extending SymmetricDS for information on how to configure an extension point. If the publish to JMS fails, the batch will be marked in error, the loaded data for the batch will be rolled back and the batch will be retried during the next synchronization run.
The following is an example extension point configuration that will publish four tables in XML with a root tag of 'sale'. Each XML message will be grouped by the batch and the column names identified by the groupByColumnNames property which have the same values.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd">
<bean id="configuration-publishingFilter"
class="org.jumpmind.symmetric.integrate.XmlPublisherDataLoaderFilter">
<property name="xmlTagNameToUseForGroup" value="sale"/>
<property name="tableNamesToPublishAsGroup">
<list>
<value>SALE_TX</value>
<value>SALE_LINE_ITEM</value>
<value>SALE_TAX</value>
<value>SALE_TOTAL</value>
</list>
</property>
<property name="groupByColumnNames">
<list>
<value>STORE_ID</value>
<value>BUSINESS_DAY</value>
<value>WORKSTATION_ID</value>
<value>TRANSACTION_ID</value>
</list>
</property>
<property name="publisher">
<bean class="org.jumpmind.symmetric.integrate.SimpleJmsPublisher">
<property name="jmsTemplate" ref="definedSpringJmsTemplate"/>
</bean>
</property>
</bean>
</beans>
The publisher property on the XmlPublisherDataLoaderFilter takes an interface of type IPublisher. The implementation demonstrated here is an implementation that publishes to JMS using Spring's JMS template. Other implementations of IPublisher could easily publish the XML to other targets like an HTTP server, the file system or secure copy it to another server.
The above configuration will publish XML similiar to the following:
<?xml version="1.0" encoding="UTF-8"?>
<sale xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
id="0012010-01-220031234" nodeid="00001" time="1264187704155">
<row entity="SALE_TX" dml="I">
<data key="STORE_ID">001</data>
<data key="BUSINESS_DAY">2010-01-22</data>
<data key="WORKSTATION_ID">003</data>
<data key="TRANSACTION_ID">1234</data>
<data key="CASHIER_ID">010110</data>
</row>
<row entity="SALE_LINE_ITEM" dml="I">
<data key="STORE_ID">001</data>
<data key="BUSINESS_DAY">2010-01-22</data>
<data key="WORKSTATION_ID">003</data>
<data key="TRANSACTION_ID">1234</data>
<data key="SKU">9999999</data>
<data key="PRICE">10.00</data>
<data key="DESC" xsi:nil="true"/>
</row>
<row entity="SALE_LINE_ITEM" dml="I">
<data key="STORE_ID">001</data>
<data key="BUSINESS_DAY">2010-01-22</data>
<data key="WORKSTATION_ID">003</data>
<data key="TRANSACTION_ID">1234</data>
<data key="SKU">9999999</data>
<data key="PRICE">10.00</data>
<data key="DESC" xsi:nil="true"/>
</row>
<row entity="SALE_TAX" dml="I">
<data key="STORE_ID">001</data>
<data key="BUSINESS_DAY">2010-01-22</data>
<data key="WORKSTATION_ID">003</data>
<data key="TRANSACTION_ID">1234</data>
<data key="AMOUNT">1.33</data>
</row>
<row entity="SALE_TOTAL" dml="I">
<data key="STORE_ID">001</data>
<data key="BUSINESS_DAY">2010-01-22</data>
<data key="WORKSTATION_ID">003</data>
<data key="TRANSACTION_ID">1234</data>
<data key="AMOUNT">21.33</data>
</row>
</sale>
To publish JMS messages during routing
the same pattern is valid, with the exception that the extension point would be the XmlPublisherDataRouter and the router
would be configured by setting the router_type of a ROUTER to the Spring bean
name of the registered extension point. Of course, the router would need to be linked through TRIGGER_ROUTERs
to each TRIGGER table that needs published.